
📊 Full opportunity report: VigilSAR Benchmark: There Is No Best Model on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The VigilSAR Benchmark demonstrates that no AI model is universally superior. Rankings vary based on user profiles focusing on capability, reliability, safety, and deployability, highlighting the importance of context in model selection.
The VigilSAR Benchmark has revealed that there is no single ‘best’ AI model for defense and intelligence applications. Instead, model rankings vary significantly based on the user’s specific requirements, such as deployment environment, compliance needs, and robustness. This finding challenges the common perception that capability scores alone determine the superior model and underscores the importance of context in AI deployment decisions.
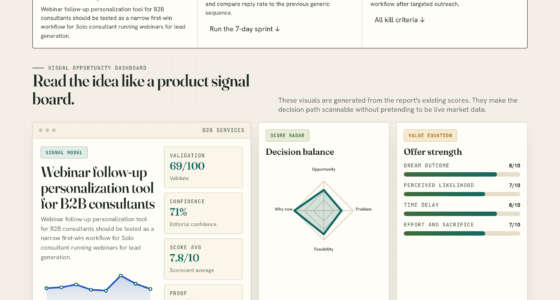
The VigilSAR Benchmark evaluates models across five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability. Unlike traditional leaderboards that focus solely on raw performance, VigilSAR emphasizes trustworthiness and practical deployment. It scores models on eight knowledge domains relevant to defense, excluding weaponization or offensive capabilities, and introduces a novel feature: re-ranking models based on different user profiles.
Three primary profiles are used: the ‘cloud frontier’ profile prioritizes maximum capability and cloud deployment; the ‘sovereign edge’ profile emphasizes models that can run on-premises or air-gapped, with a focus on EU compliance and data sovereignty; and a third profile that balances these factors. The benchmark’s design shows that a model ranking highest for one profile may fall far behind for another, illustrating that there is no one-size-fits-all model.
Importantly, the benchmark explicitly does not assess offensive or harmful capabilities. Its focus is on trustworthy, defense-relevant competence, aligning with responsible AI principles and regulatory standards such as the EU AI Act and GDPR. The developers emphasize that the benchmark is still under development and will evolve as methodologies improve.
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Why Model Selection Depends on User Needs
The VigilSAR Benchmark’s core message is that model effectiveness cannot be measured by capability alone. For defense and regulated sectors, factors such as deployment environment, compliance, safety, and reliability are often more critical than raw intelligence or speed. This shift in perspective encourages decision-makers to evaluate AI models within their specific operational contexts, reducing the risk of adopting models that may excel in tests but fail in real-world deployment.
This approach also highlights the importance of multi-dimensional evaluation in AI, moving beyond simplistic rankings. As one of the benchmark’s creators stated, “best depends on who’s asking,” meaning that a model suitable for cloud deployment may be unsuitable for air-gapped environments, and vice versa. This nuanced view aims to foster more responsible, context-aware AI adoption in sensitive fields.

AI Engineering and Agentic AI: Designing Autonomous Language Model Systems with Memory, Tools, and Safe Deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Limitations and Scope of the VigilSAR Benchmark
The VigilSAR Benchmark is in early development, with ongoing refinement of its methodology. It explicitly excludes offensive capabilities and weaponization, focusing instead on legitimate defense-relevant knowledge and trustworthy deployment. Its scope is tailored to defense, intelligence, and regulated sectors, with an emphasis on reliability, safety, and compliance.
Previous leaderboards have often prioritized raw performance, which can lead to misleading conclusions about a model’s suitability for sensitive applications. VigilSAR’s approach aims to address this gap by providing a multi-faceted, context-dependent evaluation. However, it remains a work in progress, and its rankings are subject to change as the methodology evolves.
Additionally, the benchmark does not assess offensive or harmful capabilities, aligning with responsible AI principles and regulatory standards. This focus on safety and compliance distinguishes VigilSAR from other performance-centric benchmarks and emphasizes the importance of trustworthy AI in defense contexts.
“There is no single ‘best’ model; effectiveness depends entirely on the user’s specific needs and deployment environment.”
— Thorsten Meyer, VigilSAR developer

AI Forensics
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Uncertainties and Methodology Limitations
The VigilSAR Benchmark is still in early development, and its methodology is subject to refinement. It is not yet clear how the rankings will evolve as new models and evaluation criteria are incorporated. Additionally, the benchmark currently does not assess offensive or malicious capabilities, which some critics may argue are relevant for comprehensive security assessments. The impact of these limitations on its overall utility remains to be seen.
edge AI hardware for on-premises deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for VigilSAR Benchmark Development
The VigilSAR team plans to continue refining its evaluation methodology, expanding the scope of knowledge domains, and incorporating feedback from defense and industry stakeholders. Future updates will likely include more detailed assessments of robustness and safety, as well as broader testing across different deployment environments. The team also intends to promote adoption among government agencies and regulated sectors to foster more responsible AI deployment practices.

Waveshare Tuya T5-E1 1.75inch AMOLED Round Dev Board, 466 × 466 Touch Display, QSPI Interface, Supports Smart Global AI Cloud Development Platform/Multiple Large Models, All-in-One,Without GPS Module
The T5-E1-Touch-AMOLED-1.75 a high-performance, highly integrated microcontroller development board designed.Tiny size with onboard 1.75inch capacitive AMOLED display, 6-axis…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why does VigilSAR say there is no ‘best’ AI model?
Because model effectiveness depends on the specific needs and deployment environment of the user, including factors like compliance, reliability, and hardware constraints.
How does VigilSAR evaluate models differently from other leaderboards?
It assesses multiple axes—capability, reliability, robustness, safety, and deployability—and re-ranks models based on different user profiles, emphasizing trustworthiness over raw performance.
Is VigilSAR’s benchmark complete and final?
No, it is still under development, and its methodology is expected to evolve as more data and insights become available.
Does VigilSAR evaluate offensive or harmful AI capabilities?
No, the benchmark explicitly excludes offensive, weaponized, or harmful capabilities, focusing instead on legitimate defense-relevant knowledge and trustworthy deployment.
Why is the focus on deployment environment important?
Because a model’s suitability depends heavily on where and how it is used, such as cloud versus air-gapped systems, and compliance with regional regulations.
Source: ThorstenMeyerAI.com