📊 Full opportunity report: Week Three — Foundation model vs Brownian motion. Kronos on five-minute BTC. on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
A recent test compared Kronos, a foundation model, to Brownian motion for predicting 5-minute Bitcoin moves. The results show Kronos does not outperform the traditional Brownian baseline in out-of-sample data, questioning its immediate utility for trading strategies.
Recent testing shows that the Kronos foundation model does not outperform the traditional Brownian motion model in predicting 5-minute Bitcoin price movements on out-of-sample data, challenging assumptions about the superiority of modern learned models for short-term crypto forecasting. See the detailed comparison in Week Three.
Over the past two weeks, a researcher conducted a comprehensive offline comparison of Kronos-small, an open-source foundation model trained on global exchange data, against a geometric Brownian motion baseline used by a trading bot. The test involved 497 historical trades of Bitcoin, reconstructing market context and evaluating model predictions against actual outcomes.
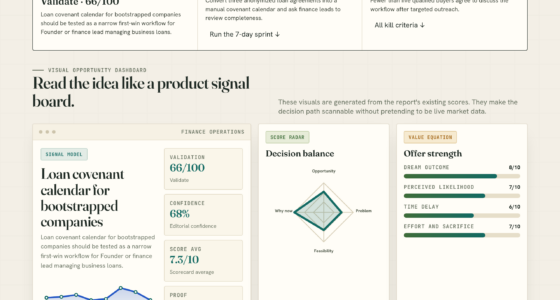
The results indicated that Kronos’s predictive performance, measured by Brier score and log-loss, was statistically indistinguishable from the Brownian baseline on out-of-sample data. Specifically, the Brier scores for Brownian and Kronos were 0.188 and 0.189 respectively, with a negligible difference of 0.0011, well within the margin of statistical noise. Consequently, the hypothesis that Kronos could provide a meaningful edge in short-term predictions was not supported by this data.
As a result, the original plan to integrate Kronos into a live trading strategy was not pursued, since the model did not demonstrate a clear advantage over the simple, well-understood Brownian approach for the specific horizon and market conditions tested.
Foundation model
vs Brownian motion.
Kronos on five-minute BTC.
all BTC · 5-min Up/Down markets
249 trades · statistically indistinguishable
signature of confident wrong predictions
the paradox · 60.7% vs 49.1% win rates
fairValuePUp(spot, openPrice, secondsLeftFrac, windowVol) formula. Matches scipy.stats.norm.cdf to three decimal places.(p_brownian, p_market, p_kronos, actual_outcome, P&L). Score on Brier + log-loss + hypothetical P&L. Sort chronologically · split into first/second half · report on both halves separately.docs/RESEARCH_PIPELINE.md. Any future candidate model gets a sibling directory in research// , reuses the same Brownian baseline, the same trade-log loader, the same OHLCV fetcher, the same metrics, the same out-of-sample split. Same gauntlet, different model, same discipline.
lower is better
lower is better
inside the noise band
docs/RESEARCH_PIPELINE.md. Publishing reproducible parameter recipes for strategies that might be marginally profitable encourages people to copy them with real money, and the prior on real-money outcomes when copying retail strategies is “they lose.” Publishing the methodology lets the next person test their own model honestly without inheriting any of mine.
By probabilistic standards · Kronos is a worse forecaster. By operational standards · Kronos is the better trader. Both interpretations are honest. Neither earns the model a place in Polybot. One of them might earn it a place, later, in TradingAgents.Thorsten Meyer AI · Week 3 · Foundation Model vs Brownian Motion
Implications for AI-Driven Short-Term Crypto Trading
This finding suggests that, at least for 5-minute Bitcoin forecasts, modern foundation models like Kronos may not yet offer a tangible edge over traditional stochastic models such as Brownian motion. This challenges expectations that large, learned models automatically outperform classical approaches in high-frequency, short-horizon trading contexts.
For traders and developers, it underscores the importance of rigorous, out-of-sample testing before deploying AI models in live environments. It also highlights that, despite advances in AI, simple models still hold value in specific, well-understood markets and timeframes.

Bitcoin Merch – Mars Lander V2 Solo Bitcoin Miner with Compac A1- Up to 350GH/s
- All-in-One Design: WiFi, RGB LEDs, BTC price ticker
- Energy Efficient: Consumes only 17 watts
- Easy Setup: Plug-and-play installation
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Background on Model Testing and Market Expectations
Over the past decade, financial modeling has evolved from classical stochastic processes to complex machine learning approaches. The Kronos model, developed by researchers and with over 25,000 GitHub stars, represents a significant effort to apply large-scale, learned models to financial time series. Prior work has shown mixed results in outperforming traditional models, especially when tested out-of-sample.
Earlier experiments with a trading bot based on Brownian motion demonstrated that most supposed ‘edges’ in short-term crypto trading tend to be artifacts or overfitted patterns that do not hold in new data. The current analysis extends this inquiry by testing whether a more sophisticated, learned model can do better in the same setting, using a rigorous, out-of-sample methodology.
“The test results show that Kronos does not outperform the Brownian baseline on out-of-sample data, indicating no immediate advantage for short-term Bitcoin prediction.”
— Thorsten Meyer

Crypto Seed Cold Storage Wallet with Engraver Pen Kit – Metal Plate and Etching Tool for Cryptocurrency Password Phrase Backup and Recovery
- All-Inclusive Crypto Storage Kit: Includes steel plate and engraving pen
- High-Quality Engraving Tool: Tungsten steel engraving pen for durability
- Fireproof and Waterproof Plate: Resists heat, water, and hacking attempts
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unanswered Questions About Model Performance and Future Prospects
It remains unclear whether different training regimes, larger models, or alternative market conditions could yield better results. The test focused solely on the small Kronos-small checkpoint and a specific 5-minute horizon, so performance in other settings is still unknown. Additionally, the potential for real-time adaptation or hybrid models combining classical and learned approaches has not been evaluated.

The Only Bitcoin Investing Book You’ll Ever Need: An Absolute Beginner’s Guide to the Cryptocurrency Which Is Changing the World and Your Finances in 2021 & Beyond (Cryptocurrency for Beginners)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for Model Evaluation and Market Testing
Further research may explore larger Kronos models, different time horizons, or live testing environments. Continuous validation against diverse market conditions will be essential to determine whether foundation models can eventually surpass traditional stochastic approaches in short-term crypto prediction. Developers and traders should remain cautious and rely on rigorous out-of-sample testing before deploying such models in live trading.

Electronic Display for Real-Time Cryptocurrency/Bitcoin/Stock Market Data, Time, Weather & Temperature, 164*28*65mm, Supports Image Upload and 30s Video Playback, App-Controlled, 960*360 Resolution
- Real-Time Data Display: Cryptocurrency, stock, time, weather updates
- Custom Image & Video Upload: Upload images and 30s videos
- App-Controlled Management: Control content and display modes
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Does this mean foundation models are useless for crypto trading?
Not necessarily. This specific test showed no out-of-sample performance advantage for Kronos in 5-minute Bitcoin predictions. Other models, settings, or longer horizons may still benefit from learned models, but rigorous testing is essential.
Could larger or differently trained Kronos models perform better?
It is possible. The current test used the small checkpoint. Future research with larger models or alternative training data might yield different results, but this remains to be seen.
Why did the traditional Brownian model perform so well?
Brownian motion is a well-understood, mathematically simple model that captures key market features at short horizons. Its robustness in out-of-sample tests makes it a strong baseline for short-term forecasting.
Is this testing method applicable to other assets or markets?
Yes. The methodology of reconstructing market context and evaluating out-of-sample predictive performance can be applied broadly, but results may vary depending on asset characteristics and market dynamics.
Source: ThorstenMeyerAI.com